Executive Summary
Chatzy AI, an agentic AI platform powering conversational and voice agents for businesses across industries, had no automated system for evaluating the quality of its AI agents' conversations at scale. The team relied entirely on manual review of chat logs — a process that was slow, inconsistent, and couldn't keep pace with growing conversation volume.
Akrta partnered with Chatzy to design and implement an automated quality monitoring pipeline that could surface failure modes, prioritize improvement areas, and ultimately close the loop between agent performance data and system optimization. What began as a lightweight LLM-as-a-Judge pilot has evolved into a comprehensive two-tier monitoring architecture now under active development.
Table of Contents
About Chatzy AI
Chatzy AI is an AI Agent Builder platform that enables businesses to create, customize, and deploy conversational AI agents across channels including WhatsApp, website chat, and social media. The platform supports both text-based conversational agents and voice agents across 50+ languages, serving use cases from customer support FAQ handling to transactional workflows like order tracking, appointment booking, and lead qualification.
Chatzy's agents are powered by LLMs trained on each client's proprietary data — knowledge bases, PDFs, website content, and structured datasets — delivered through a Retrieval-Augmented Generation (RAG) architecture. Their no-code builder allows businesses to go from data upload to live deployment without engineering resources, making the platform accessible to non-technical teams.
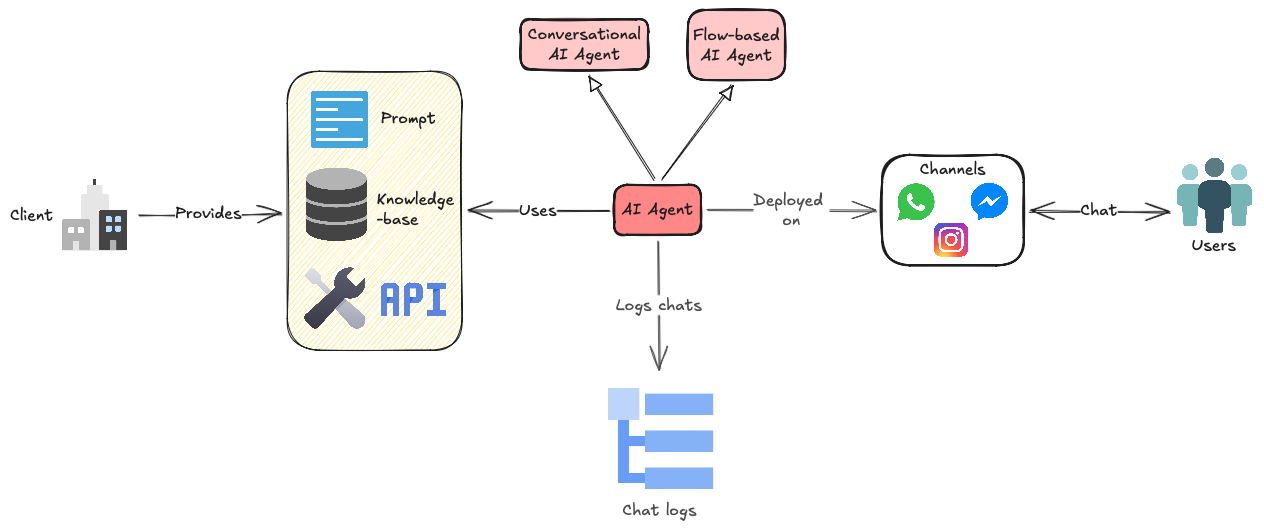
The platform serves a diverse client base, each with distinct bot types: transactional bots that execute multi-step workflows through backend integrations and external APIs (eg. CRMs), called Flow-based AI Agents, FAQ bots grounded in knowledge base articles and open-ended conversational bots that handle free-form customer interactions, both collectively referred to as Conversational AI Agents. See the schematic below to understand their platform architecture (Voice AI Agents not shown).
The Challenge
As Chatzy's client base and conversation volume grew, the gap between what their agents were doing and what the team knew about agent performance widened significantly. The core problems were:
No post-hoc analysis infrastructure. Chat logs were generated and stored but never systematically analyzed. There was no pipeline to evaluate whether conversations were being resolved, where they were failing, or why.
Manual review didn't scale. The team performed periodic manual review of individual chat transcripts — a process that was labor-intensive, inherently inconsistent across reviewers, and could only cover a fraction of total conversation volume.
Slow iteration cycles. Without automated insight into failure modes, improvements to prompts, knowledge bases, retrieval and generation systems were driven by anecdotal observation rather than data. This meant long feedback loops between identifying a problem and shipping a fix.
Chatzy needed a system that could automatically evaluate every conversation, categorize failures by type and severity, and feed structured findings back into their development process.
Discovery & Assessment
We began by conducting a thorough assessment of Chatzy's existing infrastructure and agent architecture. Chatzy's backend runs on AWS, leveraging services including managed compute and storage for their agent serving infrastructure. Their agents access fresh and domain-specific knowledge through a RAG pipeline: when an end-user sends a message, the system retrieves relevant context from the client's knowledge base (populated from uploaded documents, website crawls, and structured data), and an LLM generates a grounded response using that context.
We identified three distinct bot archetypes across their client base, each with fundamentally different quality requirements:
- FAQ Bots: Designed to answer questions grounded in a knowledge base. Success hinges on retrieval accuracy and response groundedness.
- Transactional Bots: Execute multi-step workflows (e.g., booking, order status). Success depends on accurate entity extraction, backend API reliability, and conversation flow management.
- Open-Ended Conversational Bots: Handle free-form dialogue with greater creative latitude. Success is measured by user engagement, relevance, and appropriate escalation behavior.
This discovery phase made one thing clear: a one-size-fits-all evaluation framework would miss critical failure modes specific to each bot type. The monitoring system would need to be taxonomy-aware and adaptable.
Phase 1 — Pilot: LLM-as-a-Judge Evaluation System
With the landscape mapped, we moved quickly to validate the core hypothesis: could an LLM reliably evaluate Chatzy's chat logs and surface actionable failure patterns? We designed a minimal but rigorous pilot to find out.
Architecture & Tooling
We selected DeepSeek V3.1 as the evaluation model, accessed through Together AI's API. The rationale was straightforward — for a batch evaluation workload processing hundreds of chats daily, we needed a model that was capable enough to perform nuanced conversational assessment while remaining cost-effective at scale. DeepSeek V3.1 provided the right balance of reasoning quality and per-token economics for this use case.
Evaluation Taxonomy Design
The evaluation taxonomy — the structured set of dimensions and failure categories the judge model would assess each conversation against — was arguably the most critical design decision in the pilot. We needed a framework grounded in industry best practices for conversational AI evaluation, not an ad hoc checklist.
We used Claude Opus 4.5 as a research and synthesis tool to survey established taxonomies for chatbot quality assessment, drawing from academic literature, industry benchmarks, and published case studies from companies operating conversational AI at scale. The resulting taxonomy was encoded directly into the judge model's system prompt, directing it to evaluate each chat along two axes:
- Resolution Status — Did the conversation achieve its intended outcome?
- Failure Mode Classification — If not, what went wrong? Major categories included:
INTENT_UNDERSTANDING_FAILURE— The agent misidentified or failed to identify the user's intent.KNOWLEDGE_GAP— The agent lacked the information needed to respond accurately.USER_ABANDONMENT— The user disengaged due to frustration, excessive friction, or lack of progress.BACKEND_INTEGRATION_FAILURE— API calls or system integrations failed during the conversation.ENTITY_EXTRACTION_FAILURE— The agent failed to correctly parse key entities (dates, names, order numbers, etc.).CONVERSATION_LOOP— The agent entered a repetitive cycle without advancing toward resolution.SAFETY_COMPLIANCE_ISSUE— The agent generated responses that violated content or safety guidelines.RESPONSE_RELEVANCE_DRIFT— The agent's responses, while fluent, diverged from the topic or context.
The full taxonomy and evaluation report were produced as a structured output from the batch pipeline.
Batch Execution Pipeline
The pilot ran as a daily batch job orchestrated through AWS Fargate and Amazon EventBridge. Each day, the pipeline:
- Pulled the latest chat logs from Chatzy's storage layer.
- Sampled 100 conversations each from three selected clients — chosen to represent a mix of conversational and flow-based bot types.
- Ran each conversation through the DeepSeek V3.1 judge with the evaluation taxonomy prompt.
- Aggregated results into a structured report with failure mode distributions, resolution rates, and flagged conversations.
This lightweight infrastructure choice meant the pilot could run without provisioning persistent compute or modifying Chatzy's production systems. Fargate handled the ephemeral batch workload, and EventBridge provided reliable daily scheduling: a clean, serverless execution model.
Pilot Results & Key Findings
Even with this deliberately simple setup, the pilot surfaced patterns that manual review had either missed or couldn't quantify. The results reshaped our understanding of where Chatzy's agents were struggling and directly informed the architecture of the production system.
Knowledge and content gaps dominated. The single largest category of failures across all three clients was KNOWLEDGE_GAP — conversations where the agent simply didn't have the information needed to help the user. This pointed strongly toward systemic issues in the RAG pipeline: either relevant content wasn't in the knowledge base, it wasn't being retrieved, or it was being retrieved but not effectively utilized in response generation.
User abandonment was the second major signal. A significant share of conversations ended with the user disengaging before resolution. Root cause analysis of these transcripts revealed patterns of excessive friction — the agent asking for information it should have already had, repeating clarification questions, or failing to advance the conversation toward resolution quickly enough.
Bot-type-specific patterns emerged clearly. Transactional bots showed disproportionately higher rates of entity extraction failures and backend integration issues. FAQ bots exhibited more knowledge gap and groundedness problems. This confirmed our hypothesis from the discovery phase: evaluation criteria must vary by bot archetype.
Additional failure modes included backend integration failures where API calls to client systems timed out or returned errors, conversation loops where the agent got stuck in repetitive exchanges, and response relevance drift where agents produced fluent but off-topic replies.
Phase 2 — Production: Two-Tier Monitoring System (In Progress)
The pilot made clear that a single evaluation pass couldn't serve both operational monitoring and deep diagnostic needs. We are now building a two-tier monitoring architecture that separates these concerns.
Tier 1: Surface-Level Health Metrics
The first tier operates as a broad health check across all conversations, evaluating high-level quality signals that apply universally regardless of bot type:
- Resolution Status — Was the user's issue resolved, partially resolved, or unresolved?
- Safety & Compliance — Did the agent stay within content safety guidelines and client-specific policies?
- Response Relevance — Were the agent's responses topically relevant to the user's queries?
- User Satisfaction Signals — Inferred from conversation dynamics: sentiment trajectory, engagement persistence, and explicit feedback where available.
Tier 1 is designed to run at full volume across all clients and conversations, providing a real-time dashboard of agent health.
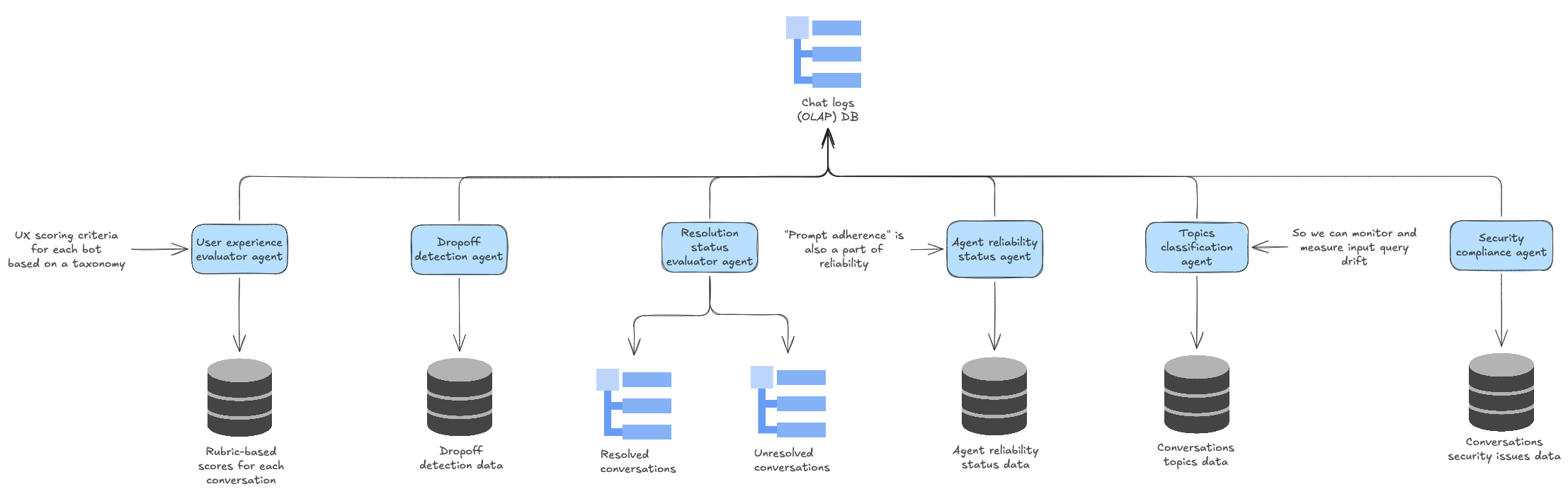
Tier 2: Root Cause Analysis Engine
Conversations flagged as unresolved or degraded by Tier 1 are escalated to a deeper diagnostic evaluation. Tier 2 applies a more computationally intensive analysis to determine why a conversation failed:
- RAG System Failure — Was relevant content missing from the knowledge base? Was it present but not retrieved? Was it retrieved but poorly utilized?
- Excessive Friction — Did the agent impose unnecessary steps or repetitive clarifications that frustrated the user?
- Conversation Flow Breakdown — Did the agent lose track of the conversational thread or fail to maintain context?
- Entity Extraction Error — Did the agent fail to parse critical user-provided information?
- Backend System Failure — Did external API calls or integrations fail?
- Escalation Handling — Did the agent fail to escalate appropriately when it should have?
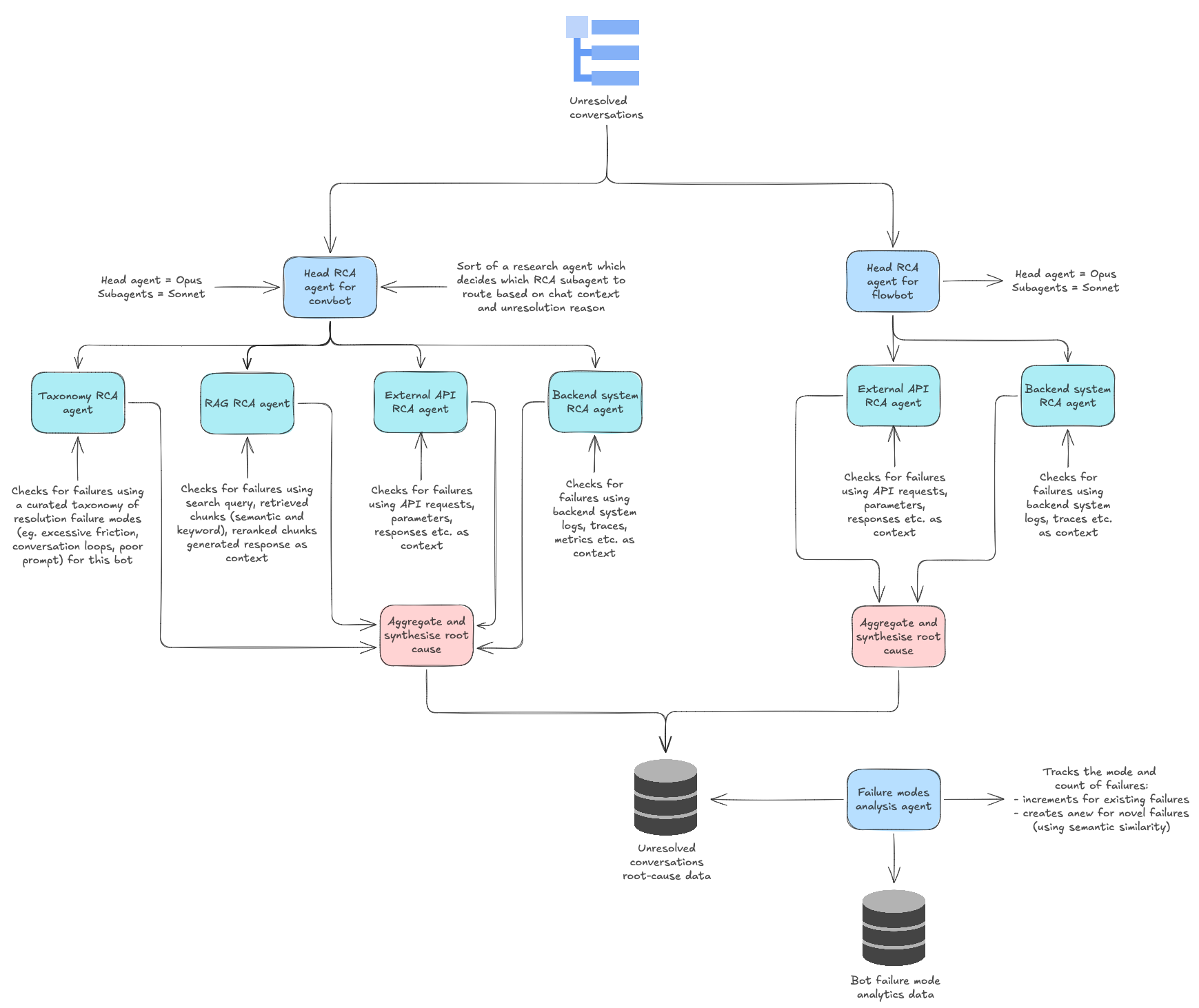
Bot-Type-Aware Taxonomy
A key architectural decision in the two-tier system is that Tier-2 applies different evaluation taxonomies depending on bot type and use case. This reflects a fundamental insight from the pilot: the definition of "quality" is context-dependent.
For an FAQ bot, groundedness relative to the knowledge base is paramount — a creative but ungrounded response is a failure. The Tier 2 taxonomy for FAQ bots therefore weights RAG retrieval accuracy, knowledge base coverage, and factual consistency heavily.
For a transactional bot, entity extraction precision and backend integration reliability are critical — the bot must correctly parse dates, order numbers, and identifiers and successfully execute API calls. Tier 2 for transactional bots focuses on extraction accuracy, API success rates, and multi-step flow completion.
For an open-ended conversational bot, the agent can afford more creative latitude, but must demonstrate relevance, appropriate escalation behavior, and user engagement. The taxonomy shifts accordingly.
What Comes Next: RAG and Backend Optimization
The two-tier monitoring system is designed not just to observe but to drive targeted optimization. The structured failure data flowing out of the system maps directly onto known improvement vectors for each component of the AI agent stack.
Drawing inspiration from published work on production RAG systems — including DoorDash's well-documented approach to their Dasher support automation, where a combination of RAG optimization, LLM Guardrails, and an LLM Judge system achieved dramatic reductions in hallucination and compliance issues — we are building an optimization roadmap that covers:
- Query Rewriting & Expansion — Reformulating user queries to improve retrieval hit rates, particularly for ambiguous or colloquial inputs.
- Hybrid Retrieval — Combining dense vector search with sparse keyword matching to capture both semantic and lexical relevance.
- Index-Aware Retrieval — Structuring the knowledge base indexing strategy around the actual query patterns observed in production conversations, rather than generic chunking approaches.
- Context Post-Processing — Filtering, re-ranking, and compressing retrieved context before it reaches the LLM to reduce noise and improve response groundedness.
- Prompt Refinement — Using failure mode data to iteratively improve agent system prompts, applying established techniques like decomposing complex instructions, using chain-of-thought scaffolding, and replacing negative constraints with positive action directives.
The monitoring system closes the feedback loop: diagnose → prioritize → optimize → measure — enabling Chatzy to move from reactive, anecdotal improvement to systematic, data-driven iteration on their AI agents.
Why This Matters
The conversational AI industry faces a well-documented quality measurement problem. Most chatbot platforms can tell you how many conversations happened. Very few can tell you how many conversations worked — and even fewer can tell you why the ones that didn't work failed.
For Chatzy, this engagement transforms quality assurance from a manual, retrospective activity into an automated, continuous process that scales with conversation volume. The shift from "we reviewed some chats and noticed issues" to "the system evaluated every conversation overnight and here are the top three areas where retrieval accuracy dropped this week" represents a fundamental change in how quickly and precisely an AI platform can improve.
This is the kind of operational infrastructure that separates AI products that plateau after launch from those that compound in quality over time.
This case study reflects an ongoing engagement. Results and system architecture will be updated as the project progresses.