Executive Summary
Riventra requested an MVP solving in the interesting though competitive market of intelligent and automated modernization of legacy codebases, so that they can be maintained and updated with new features.
Legacy modernization is a hard problem to solve due to a number of issues. The language/framework may now be obsolete or it may be hard to find professionals who can work with it. Poor documentation and/or readability of the code makes it hard for even appropriate professionals to surface workflows, use cases, business rules and implementation logic. Some legacy systems are simply too large, complex and full of bloat that manual comprehension is not feasible.
Automation holds promise to mitigate this issue and much work has happened lately in this area with a few emerging patterns like:
- Abstract Syntax Trees (AST) as knowledge graphs to surface structure and dependencies
- LLM-based understanding of legacy codebases
- LLM-based refactoring of legacy codebases
- GraphRAG for context engineering when adding features or answering questions using LLMs
Below, we explain our method and attempt at building and showcasing an MVP that works for Java codebases.
Table of Contents
A couple of hypotheses
Our approach is based on two fairly intuitive hypotheses. We nevertheless assume them not to be automatically true and ideally, they should be rigorously tested with evals and benchmarks.
Hypothesis 1: Adding new features or upgrading libraries and frameworks using LLMs is far easier when done on a maintainable codebase (properly documented, good readability etc.) with a clean and extensible architecture (no cyclic dependencies, proper abstractions etc.).
Hypothesis 2: With a proper implementation of GraphRAG on a clean and extensible codebase, a capable LLM would be able to generate accurate comprehensions of the application logic and generate the code and tests for new features without breaking existing functionality.
Thus, we first evaluate whether LLM-based code clean up holds promise in real-world repos, tested using unit/integration testing and qualitative expert analysis. Then we assess how well LLMs perform in generating accurate comprehensions and in adding new features / upgrading dependencies of a clean codebase.
We don't yet perform the two tasks in an end-to-end manner for the purposes of this MVP, as elaborated in the Conclusion.
Example codebases that we worked with
We worked with two Java codebases, one small and one medium-sized to iterate our proposed ideas and experiments on:
- spring-petclinic: a very small repo to try out initial experiments
- hibernate-orm: a medium-sized repo to see if our ideas scale well
We chose Java for the MVP owing to its strongly-typed nature that allows neat mapping of the AST into knowledge graphs.
In our approach, we first parsed the AST of the codebases into a Neo4j database according to a custom ontology that we defined as shown below:
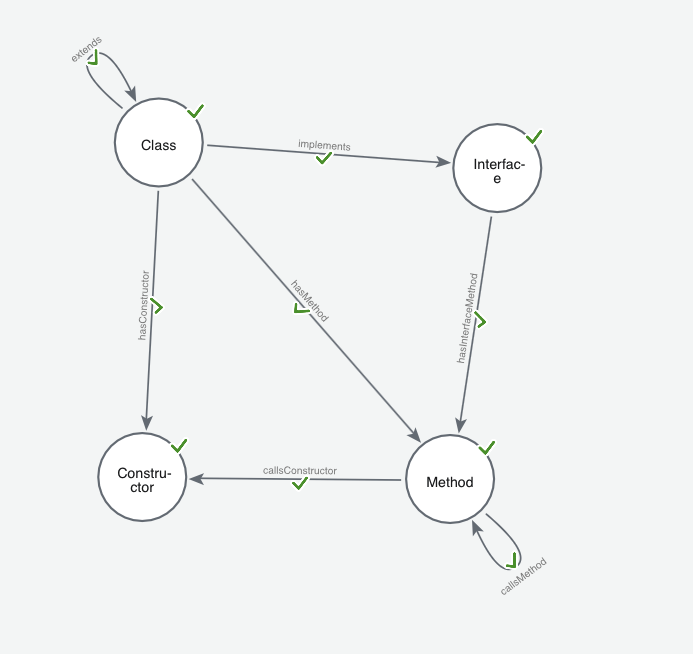
A Neo4j graph based on this ontology was then populated with the code as data. This included node properties like class/method definitions and names, line numbers, docstrings etc. The populated graph for spring-petclinic is shown below:
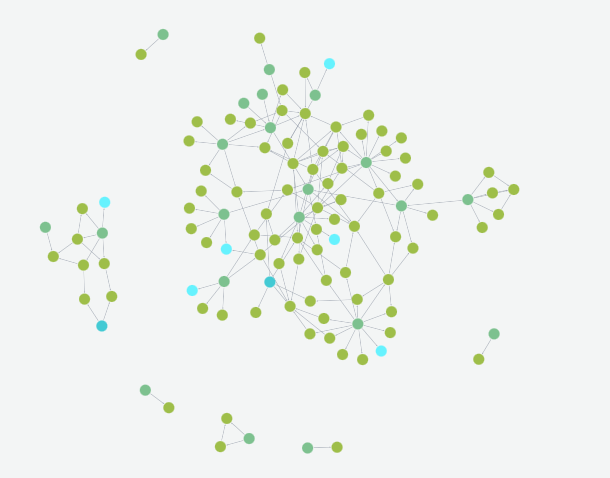
We also embedded the class/method/interface definitions and their docstrings using embedding models like text-embedding-3-large, voyage-code-3 etc.
This graph based representation provides us with valuable k-hop neighborhoods when reasoning over implementation and comprehension tasks: the class definition itself can only provide so much context, but the 1-hop or 2-hop neighborhood helps consolidate its identity and function for the LLM's context.
Cleaning up the codebase
The challenge, of course, is to maintain the exact same functionality while improving the code and refactoring the architecture to be clean and extensible. We approached this challenge in multiple steps:
Removing code-smells
Code-smells are surface-level indicators of bad coding practices like duplication, bad naming, large parameter lists etc., that may signal deeper problems in design and architecture of the application.
We made a list of code-smells that we wished to mitigate like deduplication, poor readability, unwarranted loops etc. and simply went over all the classes sequentially prompting the LLM to spot if the smell was valid for that class. For deduplication, we needed to embed and retrieve similar method/class definitions first.
Of all the smells, improving code readability using LLMs was the "simplest". We prompted the LLM to spot readability/naming issues and perform appropriate renaming of classes, variables and methods and simplification of method bodies. This obviously broke the tests and the model was then prompted to fix the offending ones in an Assess, Execute, Eval loop.
As these were rather cosmetic (although important) changes, the LLM was more or less successful in making the changes in terms of passing the tests and qualitative human evaluation. This remained true for both spring-petclinic and hibernate-orm repos, and for both the LLMs (deepseek-R1 and Gemini 2.5 Pro) that we worked with.
Improving structure
The goal here was to spot and mitigate architectural issues like "Big Ball of Mud", cyclic-dependencies, large distance from main sequence (stable abstractions principle) etc.
There is no one correct way to refactor a messy codebase because firstly, there is no clear goal to work towards. All architecture is a trade-off and there is no right or wrong in design. That said, it is sound advice to work towards the least-worst architecture that satisfies all the functional requirements without over-engineering the system.
Applying a set of refactorings is one way to simplify complex/over-engineered systems. There are two ways to do so:
- Top-down: Senior engineers first decide upon new high-level components and then refactor the existing architecture component-by-component in a Strangler Fig Pattern for example, until the desired architecture is achieved.
- Bottom-up: Problematic areas of code (according to some metric like cyclomatic complexity or number of lines etc.) are chosen to be refactored one by one, with the hope that the final architecture is a lot less complex. The chosen metric of course guides what the final architecture would look like.
No one way is better and the choice depends on the requirements. In both cases however, correct implementation of the refactoring of the chosen entity (class/method/interface etc.) is key to success.
Thus, for the purposes of the MVP, we set forth to test whether we can carry out isolated refactorings on entities in an automated manner using LLMs. The spring-petclinic project was already pretty sound architecturally, so we performed our experiments on hibernate-orm for this step.
As the latest stable version of the project was also pretty sound in structure, we gathered a bunch of PRs and asked an LLM to adjudge whether they related to a particular refactoring like "Extract class", "Extract method", "Replace Data Value With Object" etc. After so filtering the PRs, we tasked another LLM to perform that same refactoring after feeding the 1-hop or 2-hop neighborhood context retrieved using GraphRAG, again in an Assess, Plan, Execute, Test loop to prevent regressions and allow insight into the reasoning of the LLM while it performed the refactorings. We also gave the LLM access to deterministic refactoring tools like OpenRewrite to handle simple cases of refactorings.
An example refactoring of type "Replace Data Value With Object" can be found here.
While this did not always perform perfectly in terms of the ground truth in the PRs, it nevertheless came close to it often according to our in-house Java experts and a more rigorous treatment (more context than in the PR description etc.) should improve performance a lot further.
Understanding the codebase
Having gained confidence that our approach holds promise in cleaning messy codebases, the next thing to test was if we could make sense of a clean codebase.
To generate a description for the project, we first generated verbose descriptions for each class by feeding a 1-hop and 2-hop neighborhood of the class to multiple LLMs, to surface its role and function, both in isolation and in context of its neighborhood.
Armed with these class-level summaries, we then asked Gemini 2.5 Pro to generate the final project level descriptions of business logic and data flows. (Only Gemini 2.5 Pro could fit the class-level files in its context-window at the time.)
Our approach yielded unanimously acceptable comprehensions of the application logic and data-flows as adjudged by our experts, showing the promise of LLMs to parse and summarize even large codebases in a very short time when context-engineering is properly performed.
Adding features
Adding new features to a well-designed codebase is relatively simpler due to its extensibility, which allows for the application of the Open-Closed Principle that prevents regressions.
Again, in our experiments, we gathered a bunch of PRs dealing with addition of features to the hibernate-orm project and tasked the LLM to implement the feature based on the description in the PR after feeding the k-hop context (we tried different values for k) retrieved using GraphRAG. We again split up the implementation into an Assess, Plan, Execute, Test loop to prevent regressions and allow insight into the reasonings of the LLM.
According to our analysis, adding new features and tests, surprisingly succeeded more often than refactoring of existing code, possibly due to fewer interfering dependencies in the suitably extensible codebase.
Conclusion
Our experiments and methods for the purposes of this PoC, have shown that potent LLMs can perform code cleanup, comprehension and modernization reasonably well when performed individually and under controlled environments. What remains is a demonstration of these steps in an end-to-end manner to prove that they can be chained together without loss of quality. Of course a lot of hand-holding may be required when the model veers off-course especially during complex tasks like cleaning up the structure of the application itself. Nevertheless, with proper guardrails, humans in the loop and scoping of tasks, modern LLMs have been shown to scale to very large and complex tasks.